Given the HA stack is now in very good shape in Debian stretch [testing by now] we can start playing a bit with these tools.
There are 2 main points in doing so now:
- reporting bugs
- systemd integration
The last HA stack was in Debian wheezy, which didn't include systemd. Good to take that into account.
My hardware: 2 virtual machines with 1 NIC each. I called them node01 and node02.
Packages
Using aptitude. install debian packages corosync, pacemaker, pacemaker-cli-utils and crmsh.
The installation of the packages is enough for corosync to start working.
$ sudo systemctl status corosync
corosync.service - Corosync Cluster Engine
Loaded: loaded (/lib/systemd/system/corosync.service; enabled; vendor preset: enabled)
Active: active (running) since mar 2016-02-09 11:01:24 CET; 3h 7min ago
Main PID: 14610 (corosync)
CGroup: /system.slice/corosync.service
14610 /usr/sbin/corosync -f
$ sudo crm status
Last updated: Tue Feb 9 14:11:33 2016 Last change: Tue Feb 9 11:01:48 2016 by hacluster via crmd on node01
Stack: corosync
Current DC: node01 (version 1.1.14-70404b0) - partition WITHOUT quorum
1 node and 0 resources configured
Online: [ node01 ]
Full list of resources:
Basic configurationYou will need to edit the /etc/corosync/corosync.conf file:
totem
version: 2
cluster_name: lbcluster
transport: udpu
interface
ringnumber: 0
bindnetaddr: 10.0.0.0
mcastaddr: 239.255.1.1
mcastport: 5405
ttl: 1
quorum
provider: corosync_votequorum
two_node: 1
nodelist
node
ring0_addr: 10.0.0.1
name: node01
nodeid: 1
node
ring0_addr: 10.0.0.2
name: node02
nodeid: 2
logging
to_logfile: yes
logfile: /var/log/corosync/corosync.log
to_syslog: yes
timestamp: on
Note that if you choose the proper bindnetaddr directive, you can use the exact same file for all the nodes (see corosync.conf(5))
System, daemons, servicesYou may want to check that the corosync and pacemaker services are auto-started at boot time by systemd.
Do a reboot and check it:
$ sudo systemctl status corosync grep active
Active: active (running) since mi 2016-02-24 18:54:37 CET; 3min 11s ago
$ sudo systemctl status pacemaker grep active
Active: active (running) since mi 2016-02-24 18:54:38 CET; 3min 10s ago
Also, check that no firewall blocks the communication between both nodes.
Now, the status of the cluster should show both nodes working together (with no resources):
$ sudo crm status
Last updated: Wed Feb 24 19:01:13 2016 Last change: Wed Feb 24 18:43:32 2016 by hacluster via crmd on node01
Stack: corosync
Current DC: node02 (version 1.1.14-70404b0) - partition with quorum
2 nodes and 0 resources configured
Online: [ node01 node02 ]
Full list of resources:
ResourcesNow, you can start playing with the cluster resources. Below is an example of a virtual IPv6 address:
$ sudo crm configure primitive test ocf:heartbeat:IPv6addr params ipv6addr="fe00::200" cidr_netmask="64" nic="eth0" Which should give this cluster status:
$ sudo crm status
Last updated: Wed Feb 24 19:13:46 2016 Last change: Wed Feb 24 19:11:45 2016 by root via cibadmin on node02
Stack: corosync
Current DC: node02 (version 1.1.14-70404b0) - partition with quorum
2 nodes and 1 resource configured
Online: [ node01 node02 ]
Full list of resources:
test (ocf::heartbeat:IPv6addr): Started node01
Congratulations, now you have a working HA cluster with a virtual IP address, using an active/backup approach.
Please, report any bug you may find.
 The year 2016, which is about to end, has been full of work and contributions
to the FLOSS comunity.
Most of my focus goes to two important projects: Debian and Netfilter.
This is no coincidence, since my main interests in the IT world are
systems and networks.
Some numbers (no exhaustive count):
The year 2016, which is about to end, has been full of work and contributions
to the FLOSS comunity.
Most of my focus goes to two important projects: Debian and Netfilter.
This is no coincidence, since my main interests in the IT world are
systems and networks.
Some numbers (no exhaustive count):
 There are about 15 Netfilter packages in Debian, and they are maintained
by separate people.
Yersterday, I contacted the maintainers of the main packages to propose
the creation of a pkg-netfilter team to maintain all the packages together.
The benefits of maintaining packages in a team is already known to all, and
I would expect to rise the overall quality of the packages due to this
movement.
By now, the involved packages and maintainers are:
There are about 15 Netfilter packages in Debian, and they are maintained
by separate people.
Yersterday, I contacted the maintainers of the main packages to propose
the creation of a pkg-netfilter team to maintain all the packages together.
The benefits of maintaining packages in a team is already known to all, and
I would expect to rise the overall quality of the packages due to this
movement.
By now, the involved packages and maintainers are:
 Last week we had an interesting Debian meeting in Seville, Spain. This has
been the third time (in recent years) the local community meets around Debian.
We met at about 20:00 at
Last week we had an interesting Debian meeting in Seville, Spain. This has
been the third time (in recent years) the local community meets around Debian.
We met at about 20:00 at 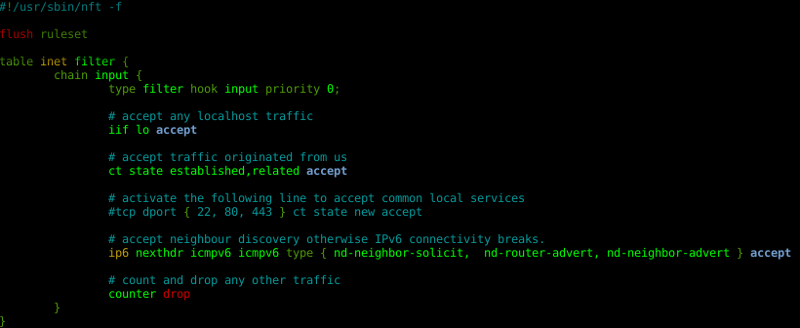 The nano editor includes nft syntax highlighting.
What are you waiting for to use nftables?
The nano editor includes nft syntax highlighting.
What are you waiting for to use nftables?

 People keep ignoring the status of the Pacemaker HA stack in Debian
Jessie. Most people think that they should stick to Debian Wheezy.
Why does this happen? Perhaps little or none publicity of the situation.
Since some time now, Debian contains a Pacemaker stack which is ready
to use in both Debian Jessie and in Debian Stretch.
Anyway, let s see what we have so far:
People keep ignoring the status of the Pacemaker HA stack in Debian
Jessie. Most people think that they should stick to Debian Wheezy.
Why does this happen? Perhaps little or none publicity of the situation.
Since some time now, Debian contains a Pacemaker stack which is ready
to use in both Debian Jessie and in Debian Stretch.
Anyway, let s see what we have so far:

 This year, I mentored a student in Google Summer of Code 2016.
I have been involved as a mentor in the Netfilter project, working
with nftables and the translation layer between iptables and nft.
The nftables framework is ready to use. I myself plan to deploy several
production firewalls during upcoming months.
Google just send me some goodies, a tshirt and a sticker.
Thanks! :-)
This year, I mentored a student in Google Summer of Code 2016.
I have been involved as a mentor in the Netfilter project, working
with nftables and the translation layer between iptables and nft.
The nftables framework is ready to use. I myself plan to deploy several
production firewalls during upcoming months.
Google just send me some goodies, a tshirt and a sticker.
Thanks! :-)
 Finally, I decided it was time to switch from blogger to jekyllrb hosted at
github pages.
My old blog at
Finally, I decided it was time to switch from blogger to jekyllrb hosted at
github pages.
My old blog at 








